eBPF: A practical intro with examples on Observability, Security & Networking
In a nutsell, eBPF (Extended Berkeley Packed Filter) is a technology that allows you to write code and load it into the Linux kernel space, in runtime, without having to actually touch the kernel code neither reboot the host machine.
It’s event driven, which gives you the flexibility to hook to any function the kernel has access to. It’s suitable to develop solutions such as observability, networking and security; it allows you to intercept, manipulate and observe any call at different stages of the kernel execution, either close to the userspace, to the drivers, or anywhere between, for example, you can react to a system call trying to writing or reading to/from the hard disk, opening a socket, sending or receiving a network package, etc.
This is the first time I’m learning about it, so I’ve defined a set of hypothetical use cases I would like to implement, to get a sense of how easy/complex, flexible and powerful eBPF is. I’m keeping this article very practical, so if you’re looking for a more detailed explanation of what eBPF is and how it works, please visit ebpf.io.
Probe Types
To get a sense on what the Linux kernel sees, I borrowed the image below from iovisor/bpftrace. On the left, you can see the uprobe/uretprobe and kprobe/kretprobe, that stands for user probe, user return probe, kernel probe, kernel return probe respectively. In the middle you can appreciate how the kernel interacts with all the component of a machine, all the way from the device drivers at the bottom, to the user applications at the top. If you want to deal from system calls to device drivers, you will need to use kernel probes; if you want to interact with system libraries and applications in the user space, you need will need to use user probes.

I’ve used BCC (BPF Compiler Collection), a toolkit for creating efficient kernel tracing and manipulation programs, reference guide. On Debian, you need to install the following packages:
sudo apt install bpfcc-tools linux-headers-$(uname -r)
Use cases
The use cases I selected are more hypothetical than practical and are far from being production ready, those are just for learning purposes.
System Security - Kill any process trying to read a specific file
Use case: I’ve very secure file /tmp/secret that I want to protect from reading, if anybody tries to open it, I will kill it (literally, in Linux jargon). So I need to listen the open event and react by sending a SIGKILL signal (9) to that adventorous process trying to violate my laws.
1from bcc import BPF
2from bcc.utils import printb
3
4BPF_SOURCE_CODE = r"""
5#define SIGKILL 9
6
7static inline bool equal_to_true(const char *str) {
8 char comparand[11];
9 bpf_probe_read(&comparand, sizeof(comparand), str);
10 char compare[] = "/tmp/secret";
11 for (int i = 0; i < 11; ++i)
12 if (compare[i] != comparand[i])
13 return false;
14 return true;
15}
16
17TRACEPOINT_PROBE(syscalls, sys_enter_openat) {
18 // args details on /sys/kernel/debug/tracing/events/syscalls/sys_enter_openat/format
19 if(equal_to_true(args->filename) == true) {
20 bpf_trace_printk("Killing process trying to access: %s\n", args->filename);
21 bpf_send_signal(SIGKILL);
22 }
23 return 0;
24}
25"""
26
27bpf = BPF(text = BPF_SOURCE_CODE)
28
29while True:
30 try:
31 (task, pid, cpu, flags, ts, msg) = bpf.trace_fields()
32 printb(b"%-6d %s" % (pid, msg))
33 except ValueError:
34 continue
35 except KeyboardInterrupt:
36 breakLoading/executing eBPF program:

Testing:

The implementation wasn’t the most effective, because I still was able to move (I could open the file in a new location) and delete the file, but you get the idea on how you can react for the sys_enter_openat system call.
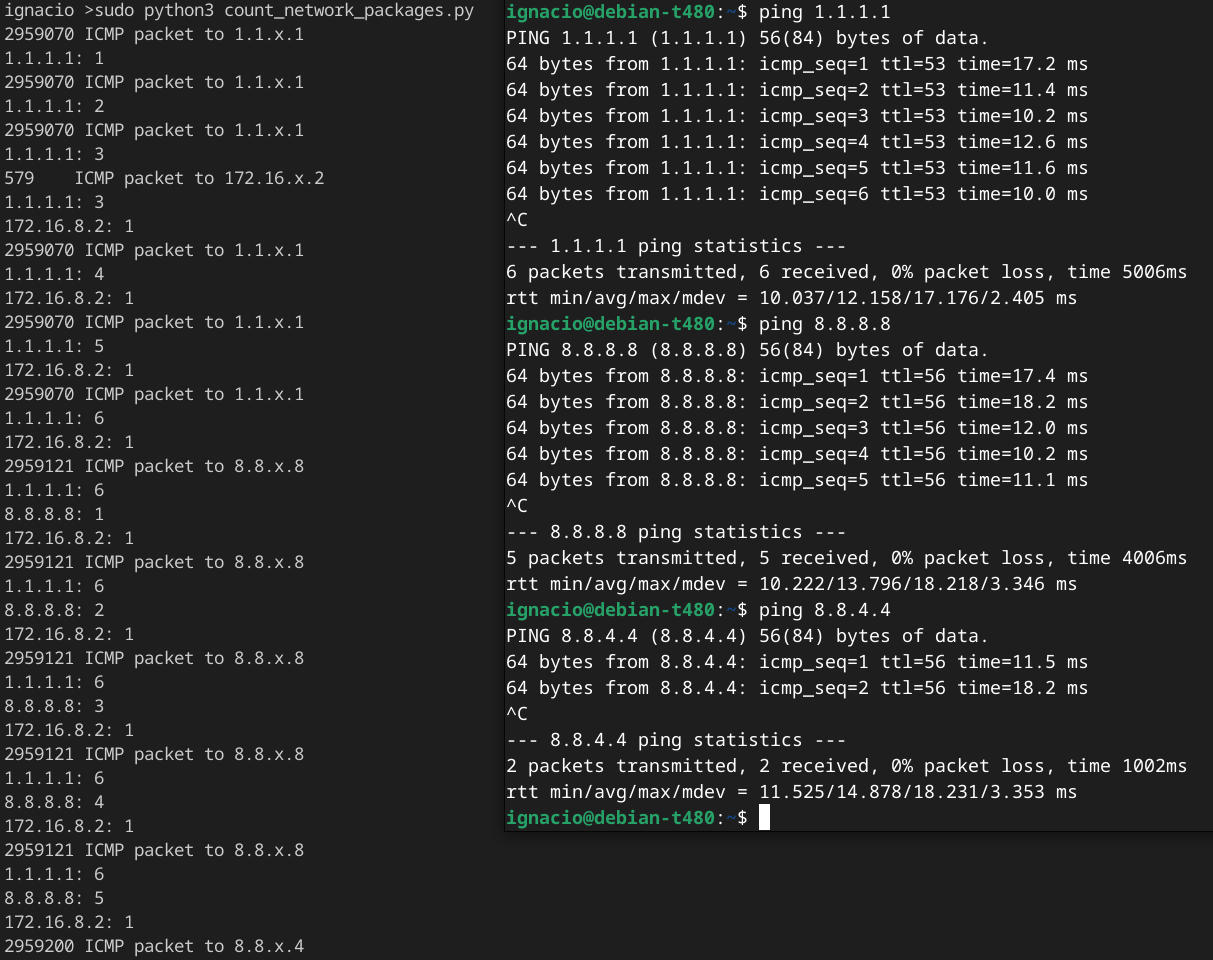
Networking - Count ICMP packages per destination IPv4
Use case: I want to detect and count how many ICMP packages are being sent any host.
This example demonstrates how you can store data in the kernel space and send it back to the user space every time.
1from bcc import BPF
2from bcc.utils import printb
3
4BPF_SOURCE_CODE = r"""
5#include <linux/ip.h>
6
7#define MAC_HEADER_SIZE 14;
8#define member_address(source_struct, source_member) \
9 ({ \
10 void* __ret; \
11 __ret = (void*) (((char*)source_struct) + offsetof(typeof(*source_struct), source_member)); \
12 __ret; \
13 })
14#define member_read(destination, source_struct, source_member) \
15 do{ \
16 bpf_probe_read( \
17 destination, \
18 sizeof(source_struct->source_member), \
19 member_address(source_struct, source_member) \
20 ); \
21 } while(0)
22
23typedef struct hist_key {
24 char ipv4_daddr[4];
25} hist_key_t;
26
27BPF_HISTOGRAM(counter, hist_key_t);
28
29static inline int do_trace(void* ctx, struct sk_buff* skb) {
30 char* head;
31 u16 mac_header;
32 u16 network_header;
33
34 member_read(&head, skb, head);
35 member_read(&mac_header, skb, mac_header);
36 member_read(&network_header, skb, network_header);
37
38 if(network_header == 0) {
39 network_header = mac_header + MAC_HEADER_SIZE;
40 }
41
42 char *ip_header_address = head + network_header;
43
44 u64 ip_version = 0;
45 bpf_probe_read(&ip_version, sizeof(u8), ip_header_address);
46 ip_version = ip_version >> 4 & 0xf;
47
48 if (ip_version == 4) { // IPv4
49 struct iphdr ip_header;
50 bpf_probe_read(&ip_header, sizeof(ip_header), ip_header_address);
51 if (ip_header.protocol == 1) { // ICMP, other fields: ttl
52 // Spliting IPv4 address, should be a better way to copy objects
53 unsigned char ip_parts[4];
54 ip_parts[0] = ip_header.daddr & 0xFF;
55 ip_parts[1] = (ip_header.daddr >> 8) & 0xFF;
56 ip_parts[2] = (ip_header.daddr >> 16) & 0xFF;
57 ip_parts[3] = (ip_header.daddr >> 24) & 0xFF;
58
59 hist_key_t key = {};
60 key.ipv4_daddr[0] = ip_parts[0];
61 key.ipv4_daddr[1] = ip_parts[1];
62 key.ipv4_daddr[2] = ip_parts[2];
63 key.ipv4_daddr[3] = ip_parts[3];
64
65 counter.increment(key);
66
67 bpf_trace_printk("ICMP packet to %d.%d.x.%d\n", ip_parts[0], ip_parts[1], ip_parts[3]);
68 }
69 }
70
71 return 0;
72}
73
74TRACEPOINT_PROBE(net, net_dev_queue) {
75 do_trace(args, (struct sk_buff*)args->skbaddr);
76 return 0;
77}
78"""
79
80bpf = BPF(text = BPF_SOURCE_CODE)
81
82while True:
83 try:
84 (task, pid, cpu, flags, ts, msg) = bpf.trace_fields()
85 printb(b"%-6d %s" % (pid, msg))
86 for i, count in bpf["counter"].items():
87 print("%d.%d.%d.%d: %d" % (i.ipv4_daddr[0], i.ipv4_daddr[1], i.ipv4_daddr[2], i.ipv4_daddr[3], count.value))
88 except ValueError:
89 continue
90 except KeyboardInterrupt:
91 breakLoading/executing & testing eBPF program:

Conclusion & what is next
Solving the use cases was definetely fun. I realized that there is so much content on the internet about this topic. I felt that BCC is just good enough for practicing, but I don’t think is a good fit for more serious, complex or production ready applications, though I haven’t explored other alternatives.
eBPF helped me to better understand how the Linux kernel works, and get to know some specific areas, such as sk_buff, the legendary Linux struct that supports the internet worlwide.